

「SC試験の午前1対策を始めたけれど、最初のページにある2進数の計算や論理演算で早くも思考が停止してしまった……」
いま、この記事を開いたあなたは、情報処理技術者試験特有の「数学的・論理的な問題」を前に、どうやって勉強を進めれば良いか悩んでいる初学者の方かもしれません。
私自身、1999年代にインフラエンジニアとしてキャリアをスタートさせ、その後CIOとしてIT投資判断を行う立場を経験し、近年は新卒エンジニアにインフラ基盤を教えてきました。しかし、正直に白状すると、これまでの実務の中で「2進数やAND演算を紙に書いて手計算する」ような場面はほとんどありませんでした。IPアドレスのサブネット設定なども、基本的にはツールを使ったり、よく使う数値を暗記したりして対応できていたのがリアルな現場の姿です。
だからこそ、いざ自身がSC試験の午前1対策を始めた際、一番最初の「基礎理論」という名の無味乾燥な計算問題の山に直面し、「なぜ実務で使わないような計算を手作業でやらされるんだ……」と、非常に面倒に感じたのを覚えています。
本記事で学べること(学習目標)は以下の通りです。
- 基数変換(2進数、16進数)や負の数の表現を、暗算ではなく「確実な作業」として処理する手順
- 午後試験の暗号技術に直結する「XOR(排他的論理和)」の根本的なメカニズムの理解
- 過去問の論理式を「真理値表」に落とし込んで確実に解く実践的アプローチ
- アルゴリズムやデータ構造の問題で脳のメモリを消費せず、機械的にトレースするテクニック
SC試験の午前1における基礎理論やアルゴリズム分野は、深く考え込む「思考」の領域ではありません。実務で手計算しないからこそ、決められたルールに従って手を動かす「作業」として割り切って処理することが、脳のスタミナを温存する最大のコツです。この記事では、私が講師時代に見てきた「初学者が陥りやすい罠」を交えながら、基礎理論の壁を最短ルートで突破するための戦略をオープンソースとして共有します。一緒に、この最初の難関をサクッと乗り越えていきましょう。
基礎理論の壁:なぜ私たちは「2進数」と「16進数」で躓くのか
午前1試験のテクノロジ系、その一番初めに登場するのが「離散数学」と「基数変換」です。私たちが普段使っている10進数(0から9までの10種類の数字を使う表現)の世界から、コンピュータが理解できる2進数(0と1のみ)、あるいは人間が2進数を扱いやすくまとめた16進数(0から9までの数字とAからFまでのアルファベット)への変換は、試験の入り口でありながら多くの受験生を挫折させる要因となっています。
コンピュータの言葉を「作業」として翻訳するマインドセット
なぜ基数変換で躓くのでしょうか。それは、多くの人が「10進数の概念のまま、2進数を直感的に理解しようとする」からです。コンピュータの内部では、すべての情報がトランジスタの電圧の高低、つまりスイッチのON(1)とOFF(0)だけで表現されています。これを人間が直感的に、感覚として理解することは不可能です。
重要なのは、2進数や16進数に「意味」を見出すのではなく、単なる「記号の変換ルール」として割り切ることです。実務において、現代のエンジニアが手計算で2進数変換を行う機会はほぼ皆無です。しかし、IPv4アドレスの枯渇問題(32ビットで表現できる上限)や、後述するメモリ管理の仕組み、文字コードの割り当てを根底で理解するためには、この「コンピュータの思考の最小単位(ビットとバイト)」を知っておく必要があります。試験においては、これを「思考」ではなく「機械的な単純作業」として処理するマインドセットに切り替えてください。
基数変換の確実な手順と「横一列の重み付け」のハック
10進数を2進数に変換する最も確実な方法は、「元の数を2で割り続け、その余りを下から順に並べる」という教科書通りの手法(すだれ算)です。しかし、午前1試験の限られた時間(1問約1分40秒)の中で、この割り算を何度も繰り返すのはタイムロスの原因となりますし、計算ミスのリスクも高まります。
私が初学者におすすめする確実な方法は、試験開始とともに問題用紙の余白に「128 64 32 16 8 4 2 1」という8ビット分の重み(ウェイト)を横一列にサッと書き出すことです。(私たちインフラエンジニアであれば、これらの数字は九九のように完全に暗記していますが、初学者が試験の極度の緊張下で計算ミスを防ぐためには、視覚化することが極めて重要です)。
たとえば、10進数の「150」を2進数にする場合、左の大きい数字から順に「引けるか?」を判定する引き算のアプローチをとります。
- 128:引ける(150 - 128 = 22)→ 下に「1」を書く
- 64:引けない(22より大きいため)→ 下に「0」を書く
- 32:引けない → 「0」を書く
- 16:引ける(22 - 16 = 6)→ 「1」を書く
- 8:引けない → 「0」を書く
- 4:引ける(6 - 4 = 2)→ 「1」を書く
- 2:引ける(2 - 2 = 0)→ 「1」を書く
- 1:引けない → 「0」を書く
このように、書き出した数字の真下に「1」と「0」を直接配置していけば、そのまま「10010110」という2進数が瞬時に完成します。わざわざ縦に2のべき乗表を書いたり割り算を繰り返すよりも、圧倒的に早くてミスが少ない、現場ライクな「作業」になります。
また、2進数を16進数に変換する場合は、2進数を「右から4桁ずつ」に区切ります。4桁の2進数は「0000」から「1111」(10進数で0から15)までの16通りを表現できるため、これをそのまま16進数の0からFに置き換えるだけです。「10010110」であれば、左半分の「1001(10進数の9)」と右半分の「0110(10進数の6)」に分割し、16進数で「96」となります。この「4桁で区切る」という法則は、MACアドレスやIPv6アドレスを読み解く際にも必須となるため、絶対に暗記してください。
負の数と小数の表現:2の補数と浮動小数点数の仕組み
コンピュータのハードウェアは「マイナス(負)」という記号を持っていません。では、どのようにして負の数を表現するのでしょうか。ここで頻出なのが「2の補数表現」です。
コンピュータ内部の演算装置(ALU)は、回路を単純化するために実は「足し算(加算)」しかできない構造になっています。引き算(減算)を行うために、「足すと桁上がりして元の桁がすべて0になる数」を作り出し、それを足すことで引き算を代行させます。これが補数です。
ある2進数の「2の補数」を求める手順は極めて機械的です。
- すべてのビット(0と1)を反転させる(これが1の補数です)。
- その結果の一番下の桁に「1」を足す。たったこれだけです。たとえば、8ビットで「00000101(10進数の5)」の負の数(-5)を求める場合、まず全ビットを反転して「11111010」とし、そこに1を足して「11111011」とします。最上位ビット(一番左の桁)が「符号ビット」として機能し、1であれば負の数であることを示します。令和5年度秋期の高度共通試験などでも、この2の補数による減算の仕組みは繰り返し出題されています。
また、小数を幅広く扱うための「浮動小数点数(IEEE 754など)」の規格も頻出です。数値を「符号部(プラスかマイナスか)」「指数部(小数点がどこにあるか)」「仮数部(実際の数値の有効数字の並び)」の3つのパーツに分けて限られたビット数に格納する仕組みです。特に重要なのは、仮数部を格納する際に最も上の桁が必ず「1」になるように小数点の位置をずらす「正規化」という処理を行う点です。この仕組みによって表現できる数値の範囲は劇的に広がりますが、同時に情報落ちや丸め誤差といった「コンピュータ特有の計算誤差」が発生する原因ともなります。これらの用語の意味と発生メカニズムをしっかりと紐づけておきましょう。
【初学者の罠】暗算への依存と「手書き」の軽視
2016年から新卒エンジニアのインフラ講師を務める中で、多くの初学者が午前1の過去問演習で全く同じミスを犯していました。それは「基数変換や補数の計算を頭の中(暗算)だけでやろうとする」ことです。
人間の脳は、0と1の単調な羅列をワーキングメモリに一時保持するようには設計されていません。暗算で処理しようとすると、必ずどこかで桁ズレを起こしたり、繰り上がりを忘れたりします。泥臭いようですが、問題用紙の余白に先ほどの「128 64 32...」を大きく書き、4桁ごとに縦線を引いて区切り、手書きで確実に変換していくことが、結果的に最も速く正確な「コスパの良い」解答法となります。試験本番の極限の緊張状態では、あなたの暗算能力は平常時の半分以下に低下することを決して忘れないでください。
論理演算と集合:SC試験を貫く「真理値表」のハック
テクノロジ系の基礎理論におけるもう一つの巨大な柱が「論理演算」です。複数の入力(0または1)に対して、定められた厳密なルールに従って一つの出力(0または1)を返す仕組みです。これはプログラミングの条件分岐(if文)の基礎となるだけでなく、ハードウェアの回路設計そのものであり、さらにSC試験の根幹をなす「暗号技術」を深く理解するための最重要知識となります。
AND、OR、NOTの基本構造と論理式の簡略化
論理演算の基本となるのは以下の3つです。
- AND(論理積): すべての入力が「1(真)」のときのみ「1」を出力する。直列回路のイメージで、両方のスイッチがONにならないと電気が通りません。
- OR(論理和): 少なくとも1つの入力が「1(真)」であれば「1」を出力する。並列回路のイメージで、どちらか一方のスイッチがONになれば電気が通ります。
- NOT(否定): 入力を反転させます。1なら0、0なら1を出力します。
これらを組み合わせたものがNAND(ANDの否定)やNOR(ORの否定)です。試験では、これらの論理演算子を複雑に組み合わせた論理式が出題され、「この式と同じ結果になる式はどれか」といった問題が頻出します。ここで役立つのが、真理値表(入力の全パターンと出力結果をまとめた表)を余白に書いてしまうことです。入力がAとBの2つであれば、パターンは(0,0)、(0,1)、(1,0)、(1,1)の4通りしかありません。複雑な式を公式を使って無理に展開・簡略化しようとするよりも、この4通りの入力を順番に代入して結果の列を作り、選択肢の式の結果と見比べる方が、確実な「作業」として処理できます。
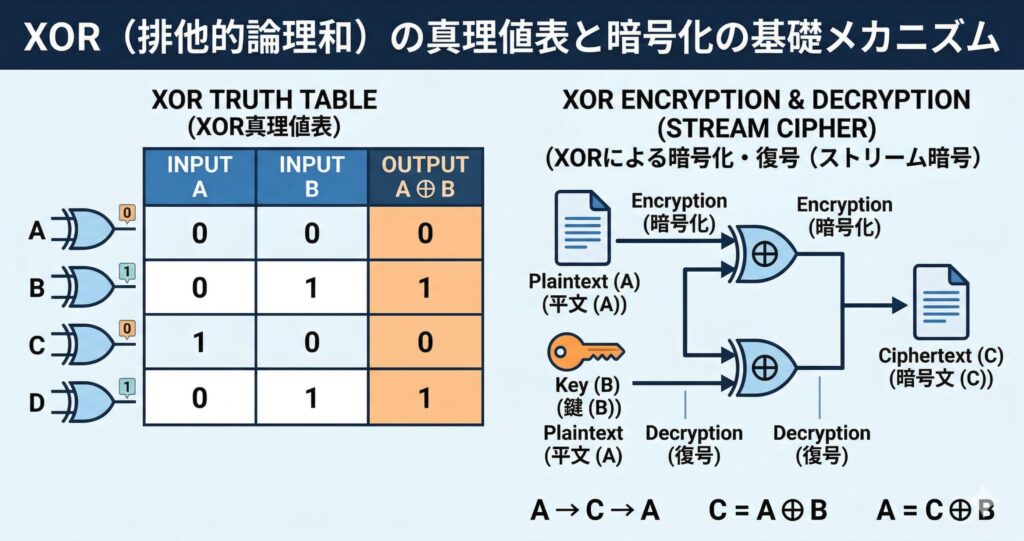
XOR(排他的論理和)の完全理解が暗号技術の土台となる
午前1対策において、私が実務の観点からも最も強調したいのが「XOR(排他的論理和)」です。XORの仕組みだけは、午後試験の暗号技術のために絶対にここで完全に理解しておいてください。
XORのルールはシンプルです。「2つの入力が『異なる』場合は1を出力し、『同じ』場合は0を出力する」。
真理値表は以下のようになります。
- 0 XOR 0 = 0
- 0 XOR 1 = 1
- 1 XOR 0 = 1
- 1 XOR 1 = 0
なぜXORがそこまで重要なのでしょうか。それはXORが持つ「可逆性(同じ鍵でもう一度演算すると完全に元に戻る)」という魔法のような性質にあります。
平文(元のデータ)をA、暗号鍵をBとします。
- 平文Aに暗号鍵BをXOR演算すると、全く意味不明な暗号文Cになります。(
) - その暗号文Cに、再び同じ暗号鍵BをXOR演算すると、なんと平文Aに戻ります。(
)これは、ワンタイムパッドや、午後試験で必ず登場する共通鍵暗号方式(AESなど)、あるいはストリーム暗号(RC4やChaCha20など)の根本的なメカニズムです。私がCIOとしてセキュリティ機器の選定を行っていた際も、暗号化処理によるシステムのパフォーマンス低下(オーバーヘッド)は常に課題でした。しかし、このXORという演算はハードウェアレベルで極めて単純かつ高速に処理できるため、暗号化アルゴリズムのコアとして多用されているのです。暗号化と復号という一見複雑なプロセスが、実は極めて単純なXOR回路の組み合わせで処理されているという事実を腹落ちさせておくことが、午後試験の長文読解への強力な伏線となります。
シフト演算とマスク処理:論理シフトと算術シフトの厳密な違い
ビット列を左右に移動させる「シフト演算」も頻出テーマです。コンピュータは掛け算や割り算を内部で行う際、このシフト演算を利用します。左に1ビットシフトすると値は2倍になり、右に1ビットシフトすると値は1/2になります。
ここで絶対に間違えてはいけないのが「論理シフト」と「算術シフト」の違いです。
- 論理シフト: 符号を考慮せず、単純にビットを移動させます。空いた桁には必ず「0」が入ります。純粋なビット列の操作や画像処理などに使われます。
- 算術シフト: 符号ビット(最上位ビット)を保持したまま移動させます。右シフトの場合、空いた桁には符号ビットと同じ値(元の数が負なら1、正なら0)が入ります。これにより、負の数を正しく1/2にすることができます。ただし、左シフトによって符号ビットが変わってしまう(オーバーフロー)条件には注意が必要です。
また、特定のビットだけを取り出したり書き換えたりする「マスク処理」も重要です。
- 特定のビットだけを取り出す:抽出したい位置を1にしたビット列と「AND演算」する。
- 特定のビットを強制的に1にする:該当位置を1にしたビット列と「OR演算」する。
- 特定のビットを反転させる:該当位置を1にしたビット列と「XOR演算」する。実務において、ネットワークプロトコルのヘッダ解析(特定のフラグが立っているかの確認)など、低レイヤの通信解析を行う際には、このマスク処理の概念がそのまま適用されます。
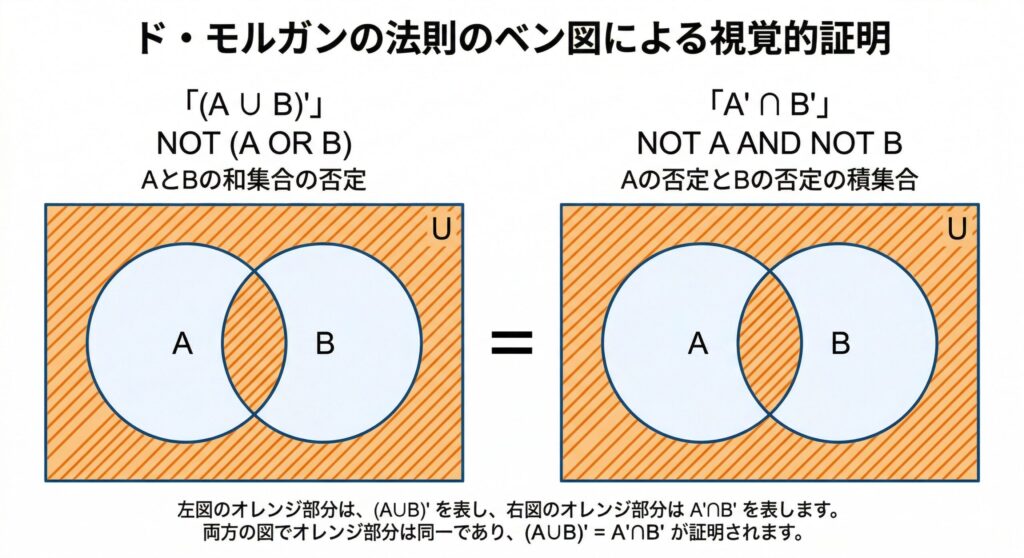
集合とベン図:ド・モルガンの法則による視覚的アプローチ
論理演算と数学的に密接に関わるのが「集合」の概念です。和集合()、積集合()、補集合()などの記号が登場します。ここでのハックは、数式や記号だけで頭の中で考えず、必ず問題用紙に「ベン図(円の重なりを描いた図)」を描いて、条件に合う部分を視覚的に塗りつぶすことです。
特に試験で頻出なのが「ド・モルガンの法則」です。
(「AまたはB」全体の否定は、「Aでない」かつ「Bでない」に等しい)(「AかつB」全体の否定は、「Aでない」または「Bでない」に等しい)これらは数式として丸暗記しようとすると試験本番の緊張でど忘れしやすいですが、ベン図を描いて該当箇所を斜線で塗りつぶせば、両者が全く同じ領域を示していることが一目瞭然で理解できます。論理式をこねくり回す前に、サッと2つの円を描く習慣をつけてください。
【実践編】過去問の論理式を「真理値表」でハックする
論理演算は公式による計算ではなく、真理値表を書いて作業として処理する。この戦略を確実なものにするため、高度試験の午前1(応用情報技術者試験からの共通出題)で実際に出題された過去問を題材に、試験本番でどのように手を動かすべきか、その具体的な手順を概説します。
【過去問】令和3年度 春期 応用情報技術者試験 午前 問2
まずは、実際の試験で出題された以下の問題を見てください。
【問題】
A, B, C をブール変数とするとき、論理式 と等しいものはどれか。
(※ は論理積(AND)、 は論理和(OR)、 は の否定(NOT)を表す)
ア:
イ:
ウ:
エ:
ブール代数の公式は捨てろ。4つの「代入作業」に徹する
この問題を見たとき、初学者がやりがちなのが「ブール代数の公式(分配則や吸収則など)を使って、式を美しく整理しようとする」ことです。
例えば、 の部分を A でくくり出して にし、B と「B の否定」のORは必ず1になるから……と「思考」を始めてしまいます。
しかし、お恥ずかしい話ですが、私自身がSC試験の過去問演習を始めた当初、まさにこの罠にはまりました。公式を使って数学的に美しく解こうと粘った結果、いたずらに時間を浪費し、焦りからバー(否定記号)の見落としやANDとORの取り違えといったケアレスミスを連発してしまったのです。試験本番の極度の緊張状態では、このリスクがさらに跳ね上がります。
ここは思考を完全に止め、問題用紙の余白に A と B の「0」と「1」の組み合わせ(全4パターン)を書き出し、愚直に代入していく「作業」に切り替えます。(※問題文に C がありますが、式には登場しないダミー変数なので無視します)
問題の論理式を検証する
与えられた式:
この式は、3つの掛け算(AND)ブロックが足し算(OR)で繋がっている構造です。どれか1つのブロックでも「1(真)」になれば、全体が1になります。全4パターンの入力を一つずつ検証します。
パターン1:A=0, B=0 の場合
パターン2:A=0, B=1 の場合
パターン3:A=1, B=0 の場合
パターン4:A=1, B=1 の場合
計算の結果、出力は上から順に「0, 1, 1, 1」となりました。
選択肢(ア〜エ)の真理値表を作成して照合する
問題の論理式が「0, 1, 1, 1」になることがわかりました。次に、選択肢のア〜エについても同様に真理値表を作って比較します。
- ア:
(論理和)どちらかが1なら1 - イ:
(論理積)両方が1のときのみ1 - ウ:
Aの否定とBの否定の論理和 - エ:
AとBの論理積の結果を否定
これらを表にまとめると以下のようになります。
| 入力パターン (A,B) | 問題の式 | ア:A+B | イ:A⋅B | ウ:A+B | エ:A⋅B |
| A=0, B=0 | 0 | 0 | 0 | 1 | 1 |
| A=0, B=1 | 1 | 1 | 0 | 1 | 1 |
| A=1, B=0 | 1 | 1 | 0 | 1 | 1 |
| A=1, B=1 | 1 | 1 | 1 | 0 | 0 |
表を見比べれば一目瞭然です。問題の式と全く同じ出力結果(0, 1, 1, 1)になっているのは、「ア:」のみであり、これが正解となります。
また、この表を作るともう一つの重要な事実に気づけます。「ウ」と「エ」の出力結果が全く同じ「1, 1, 1, 0(NAND回路の動き)」になっています。これは、基礎理論で必ず登場する「ド・モルガンの法則( )」が成立している明確な証拠です。真理値表を書くという作業は、単に正解を導くだけでなく、こうした公式の裏付けを自分の目で事実として確認できるというメリットもあります。
アルゴリズムとデータ構造:思考を捨てて「トレース」に徹する
テクノロジ系基礎理論の最終関門であり、最も多くの受験生が苦手意識を持つのが「データ構造」と「アルゴリズム」です。ここでは、大量のデータをコンピュータがいかに効率よくメモリ上に配置し、素早く探し出すか(探索)、あるいは順番に並べ替えるか(整列)という、プログラミングの根幹が問われます。
データ構造の選択:配列と連結リスト、スタックとキュー
プログラムがデータを記憶領域(メモリ)に保持する際の構造には、明確な用途に応じた複数のパターンがあります。
- 配列(Array): メモリ上の連続した領域にデータを順番に並べる構造です。インデックス(要素番号)を指定すれば、先頭からのオフセット計算により一瞬でデータにアクセスできます。しかし、途中にデータを挿入したり削除したりする場合、それ以降のすべてのデータをズラす必要があり、処理負荷が非常に大きくなります。
- 連結リスト(Linked List): データ本体と、次のデータがメモリ上のどこにあるかを示す「ポインタ(アドレス情報)」をセットで保持する構造です。データ自体はメモリ上にバラバラに散らばっていても構いません。ポインタの書き換えだけでデータの挿入・削除が高速に行えますが、目的のデータを探すには先頭からポインタを順番にたどる必要があり、ランダムアクセスには不向きです。双方向リストの場合は、前後のポインタを持つため逆順の探索も可能になります。
現代のPythonやRuby、JavaScriptなどの高級言語では、これらのメモリ管理やデータ構造の物理的な配置は言語仕様によって完全に隠蔽(抽象化)されています。そのため、近年学習を始めた新卒エンジニアは「なぜわざわざリストやポインタを意識するのか」と疑問を持ちがちです。しかし、限られたメモリリソースを極限まで使い切り、かつバッファオーバーフローなどの深刻な脆弱性を生み出さないセキュアなシステムを構築する際、このデータ構造の物理的な振る舞いの理解が不可欠なのです。
また、データを出し入れする順序のルールとして以下の2つも頻出です。
- スタック(Stack): 後から入れたデータを最初に取り出す(LIFO: Last In First Out)構造です。机の上に本を積み上げ、上から取っていくイメージです。OSの割り込み処理時のレジスタ退避や、関数の再帰呼び出しにおけるローカル変数の保持などに使われます。データを追加することを「Push」、取り出すことを「Pop」と呼びます。
- キュー(Queue): 最初に入れたデータを最初に取り出す(FIFO: First In First Out)構造です。レジの順番待ちの列のイメージです。ネットワークのルータにおけるパケット転送のバッファや、プリンタの印刷待ち行列(スプール)、OSのタスクスケジューリングなどで広く使われます。追加を「Enqueue」、取り出しを「Dequeue」と呼びます。
木構造とデータ探索:二分探索木とハッシュ法のメカニズム
データを階層的に管理する「木構造(Tree)」も重要です。特に、一つの親ノードから最大で2つの子ノードが分岐する「二分木(Binary Tree)」がよく出題されます。
試験でよく問われるのはデータの巡回(なぞり方)の順序です。
- 先行順(プレオーダー): 親 → 左の子 → 右の子
- 中間順(インオーダー): 左の子 → 親 → 右の子
- 後行順(ポストオーダー): 左の子 → 右の子 → 親これらの巡回ルールを問う問題が出たら、木構造の図のノードの周りを線でなぞりながら、どのタイミングでノードを「訪問した」と判定するかを物理的に書き込むことで確実に解けます。
また、データを高速に探し出す「探索アルゴリズム」において、二分探索とハッシュ法は極めて重要です。
- 二分探索(Binary Search): あらかじめデータが規則に従って整列(ソート)されていることが前提です。中央のデータを確認し、探しているデータがそれより大きいか小さいかを判断して、探索範囲を半分に絞り込む作業を繰り返します。100万件のデータがあっても、わずか20回程度の比較で目的のデータを見つけることができる極めて優秀なアルゴリズムです。
- ハッシュ法(Hash Search): 探索するデータの値そのものを関数(ハッシュ関数)にかけて計算し、その計算結果をそのままメモリの格納アドレス(インデックス)として使用する手法です。計算一発でデータの場所が特定できるため、データ量に関わらず最速で探索可能です。ただし、異なるデータから同じハッシュ値が計算されてしまう「シノニム(衝突)」が発生した際の解決法(オープンアドレス法やチェイン法)とセットで理解しておく必要があります。
整列(ソート)アルゴリズムの網羅的理解とオーダー記法(Big-O)
バラバラのデータを昇順または降順に並べ替える「整列(ソート)アルゴリズム」は、それぞれの処理手順の特徴と、計算量を示す「オーダー記法(記法)」を紐づけて暗記する必要があります。オーダー記法とは、データ量 が増加した際に、処理時間がどの程度増加するかを示す指標です。
: データ量に関係なく処理時間は常に一定です。ハッシュ法での理想的なデータアクセスが該当します。: データ量に比例して処理時間が増加します。配列の先頭から順番に確認する線形探索などが該当します。: データ量が増えても、処理時間の増加は非常に緩やかです。前述の二分探索がこれに当たります。: データ量が2倍になると処理時間は4倍になり、データ量が多いと実用に耐えません。以下の単純なソートアルゴリズムが該当します。- バブルソート(基本交換法): 隣り合う要素を比較し、条件に合わなければ交換する作業を末尾から先頭に向かって繰り返す手法。
- 選択ソート(基本選択法): 未整列のデータの中から最小値(または最大値)を探し出し、未整列部分の先頭と交換する手法。
- 挿入ソート(基本挿入法): 未整列のデータを取り出し、すでに整列済みのデータ群の正しい位置に挿入していく手法。
: 高速なソートアルゴリズムの計算量です。試験では以下の特徴を確実に押さえてください。- クイックソート: 適当な基準値(ピボット)を選び、それより小さいグループと大きいグループに分割する作業を再帰的に繰り返す手法。平均的に最速ですが、最悪のケース(すでにソート済みのデータなど)では
に悪化する特徴を持ちます。 - マージソート: データを細かく分割し、それらを整列させながら併合(マージ)していく手法。外部記憶装置(ディスク)上のソートに有効です。
- ヒープソート: 未整列のデータを「ヒープ」と呼ばれる特殊な順序木構造に構成し、そこから最大値(または最小値)を順次取り出して整列する手法。
- クイックソート: 適当な基準値(ピボット)を選び、それより小さいグループと大きいグループに分割する作業を再帰的に繰り返す手法。平均的に最速ですが、最悪のケース(すでにソート済みのデータなど)では
午前1試験では、細かいプログラムのコードを追う問題よりも、「このアルゴリズムの名前、特徴、そして計算量」の組み合わせを問う知識問題が多いため、これらを体系的に整理して丸暗記するだけで確実に得点源になります。
擬似言語と流れ図は「読解」ではなく「状態遷移の記録」
午前1試験のアルゴリズム分野で最も時間を奪われるのが、フローチャート(流れ図)やIPA独自の擬似言語を用いて、プログラムの実行結果や途中の変数の値を問う問題です。ここで初学者が陥る最大の罠が「アルゴリズムの意図や全体像を、ソースコードを読んで頭の中だけで理解しようとする」ことです。
試験で出題されるアルゴリズムは、わざと複雑なループ条件で書かれていたり、一部に穴埋めがあったりします。これを「読解」しようとすると膨大な時間を消費し、ループの回数を1回数え間違えただけで致命的な失点に繋がります。
対処法はたった一つです。問題用紙の余白に「変数A」「変数B」「カウンタi」といった変数の箱(表)を書き、ループ処理が1回終わるごとに変数の値がどう変化したかを、1行ずつ愚直に「記録(トレース)」することです。コードの意図などの思考を介在させず、書かれている命令文をそのまま単純作業のルールとして実行し、変数の最新の値を消しゴムで消して書き換えるのではなく、履歴が残るように下へ下へと書き連ねていく。この「状態遷移の記録」に徹することが、ケアレスミスを防ぎ、確実に正解を導き出す唯一のアプローチです。
過去問に学ぶアルゴリズム問題の「後回し」戦略
ここまで基礎理論や各種アルゴリズムの解き方を網羅的に解説してきましたが、午前1試験のタイムマネジメントにおいて最も重要な、実践的な戦略をお伝えします。
それは、「流れ図のトレース問題や、複雑な真理値表を組み立てる必要のある計算問題が出たら、本番では『一番最後』に回す」ということです。
基礎理論の計算問題やトレース問題は、時間をかければ確実に解けることが多い反面、焦っていると簡単な足し算やループ回数のミスで失点し、しかもその1問に5分以上の貴重な時間を浪費してしまう危険性があります。午前1試験は全30問中、18問正解(60点)すれば通過できる足切り試験に過ぎません。まずは知識だけで5秒で解ける暗記問題(ネットワークプロトコルやセキュリティ用語、マネジメント・ストラテジ系の用語など)をすべて拾い集め、確実な得点と精神的な余裕、そして残り時間を確保してください。すべての知識問題を解き終えてから、余った時間を全額投資して計算問題の「作業」に没頭する。この解答順序を守るだけで、時間切れによるパニックを確実に防ぐことができます。
まとめ:実務でも試験でも「確実な検証」が勝つ
いかがだったでしょうか。一見すると難解な数式や記号の羅列に見える「基礎理論」の分野も、その裏側にある「コンピュータが物理的な制約(0と1しか扱えない、足し算しかできない、メモリ容量に限りがある)の中でいかに効率よく計算し、データを保持するか」という根本的なメカニズムを知れば、単なるパズルのルールに過ぎないことがお分かりいただけたかと思います。
私がインフラエンジニアとして現場に出た頃は、これらの基礎理論を手計算でゴリゴリ解くような場面はありませんでしたが、だからといって無価値だったわけではありません。CIOとして全社のアーキテクチャやセキュリティ投資を判断する際、あるいは新人にシステムのボトルネックを教える際、この「コンピュータの根本的な振る舞い」を理解しているかどうかが、プロフェッショナルとしての視野の広さを決定づけていました。
また、インフラエンジニアとしてルータやファイアウォールの複雑なアクセス制御リスト(ACL)を設計する際、「この送信元とこの宛先を拒否して、特定のポートだけは許可して……」と頭の中だけで論理を組み立てようとすると、必ず設定の抜け漏れ(セキュリティホール)が生まれます。考え得るすべての通信パターンをスプレッドシートに書き出し、一つひとつテストして事実ベースで検証していくのが現場の鉄則でした。
今のあなたがこれらを「学問」として深く探求しすぎる必要はありません。SC試験の午前1対策における基礎理論は、あくまで試験を通過するための「作業」です。
- 2進数の計算は暗算を捨てて「128 64 32...」の横のウェイトを引き算で処理する。
- 負の数は「ビット反転+1」の2の補数で機械的に求める。
- 論理演算は「公式を使って美しく解く」必要はない。「真理値表」と「ベン図」を書き出し、事実ベースで視覚的に処理する。
- 午後試験のために、XOR(排他的論理和)の可逆性だけは絶対に腹落ちさせる。
- アルゴリズムのトレース問題は、試験の最後に回して愚直に状態遷移を書き出す。
これらの「型」を徹底し、貴重な脳のスタミナを消費せずに、淡々と正解を積み重ねていきましょう。絶対に諦めず、共に「SC試験合格」を目指して歩みを進めましょう!
本記事は情報処理安全確保支援士(SC)試験対策を目的として作成しています。