

システムの開発が完了し、サービスが稼働し始めると、真の戦いが幕を開けます。最新のセキュリティ機器を導入し、堅牢なアーキテクチャを設計したとしても、日々の「運用」が疎かになれば、システムはあっという間に脆弱なものへと変貌します。
セキュアな開発手法や最新のクラウドセキュリティと並び、後半のシステムライフサイクルを支える運用フェーズは特に重要です。ログの監視、インシデント発生時の対応、日々のパッチ適用、物理的な入退室管理まで——これらは決して派手な技術ではありません。しかし、サイバー攻撃から組織を最後まで守り抜くのは、こうした「泥臭い」運用対策の徹底です。
本記事では、システム運用・管理、インシデント対応、物理的セキュリティに至るまでの広範な知識を整理し、現場で求められる実践的なセキュリティ対策の全体像を解説します。
ログ分析とインシデント対応|セキュリティ運用の核心
システム運用において、最も重要な情報源となるのが「ログ」です。ログは、システム内で誰が・いつ・何をしたのかを記録する客観的な証拠であり、サイバー攻撃の早期発見や被害範囲の特定に欠かせません。
主要ログの種類とSIEMによる相関分析
システムを構成する各機器やソフトウェアは、それぞれ異なる形式でログを出力します。代表的なログの種類とその役割を正確に把握することが、運用の出発点です。
- Syslog(ネットワーク機器・Linuxサーバー)
ルーター、スイッチ、ファイアウォールなどのネットワーク機器や、Linux OSが出力する標準的なメッセージングプロトコルです。システムのエラー情報や構成変更の履歴が記録され、インフラ全体の健康状態を把握するために不可欠です。 - Webサーバーログ(Apache / Nginxなど)
クライアントからのHTTPリクエスト(アクセス日時・IPアドレス・リクエストURI・ステータスコードなど)を記録します。「404 Not Found」の異常な連続はディレクトリトラバーサル攻撃の探索、「500 Internal Server Error」はSQLインジェクションによるバックエンドの異常終了など、Webアプリケーションへの攻撃の兆候を読み取る一次情報となります。 - Windowsイベントログ
Windows OS上で発生したシステム・セキュリティ・アプリケーションに関するイベントを記録します。特に「セキュリティログ」におけるログイン成功・失敗の記録は、ブルートフォース攻撃や不正アクセスの検知に直結します。
これらのログは単体でも有用ですが、大規模なシステム環境ではログの量が膨大になり、人間の目で不審な挙動を見つけ出すことは現実的ではありません。そこで活躍するのがSIEM(Security Information and Event Management)です。
SIEMは、ファイアウォール・プロキシ・OS・データベースなどあらゆる機器からログを一元的に収集します。そして、「ファイアウォールでブロックされた直後に、同じIPアドレスからWebサーバーの管理者ページへアクセスが成功している」といった、異なる機器間のログを掛け合わせた「相関分析」を自動で行い、真の脅威をあぶり出します。
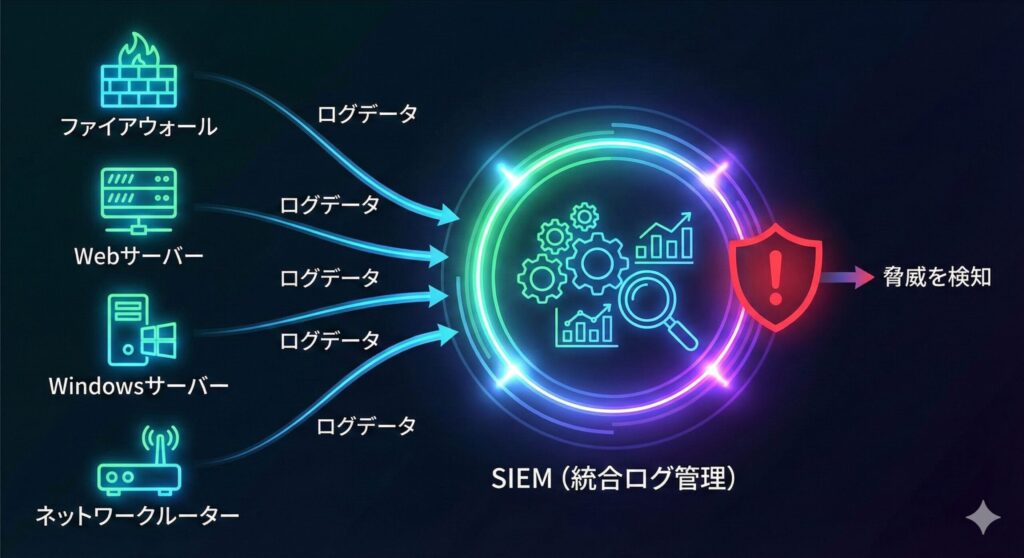
インシデントレスポンスの4フェーズと初動対応の鉄則
どれだけ強固な予防策を講じても、サイバー攻撃を100%防ぐことはできません。インシデントが発生した際に被害を最小限に抑え、迅速に業務を再開するための手順が「インシデントレスポンス」です。対応は大きく4つのフェーズに分けられます。
- 準備・検知(Preparation & Detection)
平時から連絡網を整備し、ログ監視ツール(SIEMなど)を用いて異常を検知します。誤検知(False Positive)を排除し、真のインシデントかどうかを見極めるトリアージの力が問われるフェーズです。 - 封じ込め(Containment)
インシデント検知直後に行う、最も緊急性の高いフェーズです。マルウェアに感染した端末をネットワークから物理的・論理的に切り離す、攻撃者が利用しているアカウントを直ちに無効化するなど、被害の拡大を止める「止血」を最優先に行います。 - 根絶(Eradication)
システム内部に侵入した脅威を完全に取り除きます。マルウェアの駆除、不正に作成されたバックドアの削除、攻撃の起点となった脆弱性(パッチ未適用など)の修正が対象です。根本原因を解決しなければ、復旧後も再び攻撃を受けることになります。 - 復旧・教訓(Recovery & Lessons Learned)
クリーンになったシステムを稼働状態に戻し、業務を再開します。バックアップからのデータリストア後は、今回のインシデントを振り返り、プロセスやルールの改善点を次の「準備」フェーズへと繋げます。
CSIRTとSOCの連携、そしてデジタルフォレンジック
インシデント対応を組織的に推進するために、CSIRT(Computer Security Incident Response Team)とSOC(Security Operations Center)という2つの専門部隊が存在します。
- SOC(ソック) は24時間365日体制でネットワークや機器のログを監視し、サイバー攻撃の兆候をいち早く「検知・分析」する監視のスペシャリストです。
- CSIRT(シーサート) はSOCからのアラートを受け、組織全体を巻き込んで被害の最小化・原因究明・外部機関(警察や関係省庁)への報告など「対応全般」を指揮する司令塔です。
インシデントの全容を解明するには、端末やサーバーに残された電子的な証拠を保全・分析するデジタルフォレンジックの技術も不可欠です。インシデント発覚時に慌ててサーバーを再起動してしまうと、メモリ上に展開されていたマルウェアの痕跡や直近のネットワーク接続情報(揮発性データ)が消滅します。「揮発性の高いデータから優先して保全する(証拠保全の原則)」 ことは、運用担当者が絶対に守るべき鉄則です。
学習の全体像=進むべき道筋がひと目で分かる
〈セキュリティ学習メール〉
システムを止めない!運用管理とBCP/DR戦略
システム運用のもう一つの重要な柱が「可用性(Availability)」の維持です。システムを安全かつ安定して稼働させ続けるための戦略を整理します。
泥臭いが最強の盾:パッチ管理とIT資産管理
サイバー攻撃の多くは、すでに発見・公表されているソフトウェアの脆弱性を突いて行われます。「修正プログラム(パッチ)を迅速に適用する」という基本行動こそが、最強のセキュリティ対策と言っても過言ではありません。
しかし大規模な組織ほど、この基本的な作業が困難を極めます。「社内にどんなサーバーが何台あるのか」「誰がどのバージョンのソフトウェアを使っているのか」が把握できていなければ、パッチの適用漏れは必ず発生します。これを防ぐのがIT資産管理です。
ハードウェア(PC・スマートフォン・サーバー)とソフトウェア(OS・アプリケーション・ライセンス)の棚卸しを定期的に行い、正確な資産台帳を維持すること——一見地味で泥臭い作業ですが、自組織のIT環境を完全に可視化して初めて、脆弱性に対する正しい防御線を張ることができます。
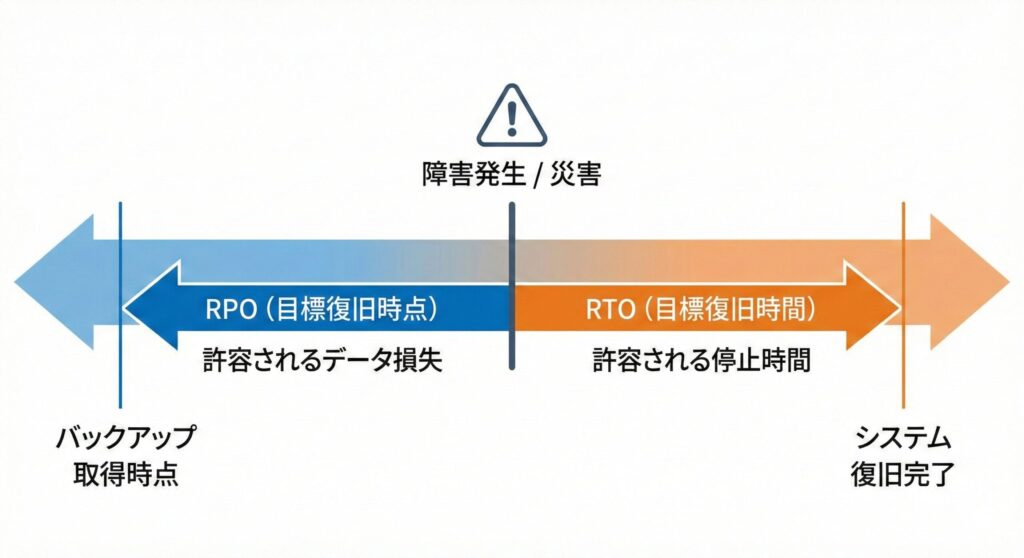
RPOとRTOから導き出すバックアップ戦略
ランサムウェア(身代金要求型マルウェア)による被害が急増する現代において、バックアップの重要性はかつてないほど高まっています。効果的なバックアップ戦略を立てるために不可欠な2つの指標が「RPO」と「RTO」です。
- RPO(Recovery Point Objective:目標復旧時点)
「過去のどの時点のデータまで戻せれば、業務への影響を許容できるか」を示す指標です。RPOが「1時間」であれば、1時間ごとにバックアップを取得する必要があります。データ喪失の許容度を表します。 - RTO(Recovery Time Objective:目標復旧時間)
「システムが停止してから、どれくらいの時間で復旧させなければならないか」を示す指標です。RTOが「24時間」であれば、障害発生から24時間以内にシステムを再稼働させる手順と設備を用意する必要があります。ダウンタイムの許容度を表します。
バックアップ手法(フルバックアップ・差分バックアップ・増分バックアップ)や保存先メディアの選定は、すべてこのRPOとRTOの要件を満たすように設計されます。ランサムウェア対策としては、ネットワークから物理的に切り離されたメディア(テープなど)に保存するオフラインバックアップや、一度書き込んだら変更・削除ができないWORM(Write Once Read Many)ストレージの活用が有効です。
災害を乗り越えるBCP(事業継続計画)とDR(災害復旧)
自然災害や大規模なサイバー攻撃によって中核システムが壊滅的な被害を受けた場合、組織の存続そのものが危ぶまれます。この最悪の事態を想定し、あらかじめ対策を定めておくのがBCPとDRです。
BCP(Business Continuity Plan:事業継続計画) は、組織全体のビジネスをどう継続するかという「事業戦略」の視点を持ちます。システムが使えない期間中、紙とペンを使った手作業でどのように顧客対応を行うか、代替のオフィスをどこに構えるかといった、非IT部門を含めた包括的な計画です。
一方、DR(Disaster Recovery:災害復旧) は、BCPを実現するための「ITシステムの復旧戦略」です。遠隔地にバックアップデータセンター(サイト)を構築し、メインセンターが被災した際に速やかにシステムを切り替える仕組みを指します。主な方式は以下の3種類で、コストとRTOのバランスを考慮して選定します。
- ホットサイト:メインと同等のシステムを常に稼働させておく方式。RTOは最短だがコストが高い。
- ウォームサイト:機器だけ用意しておき、データは適宜同期する方式。コストとRTOのバランス型。
- コールドサイト:スペースと電源だけを確保しておく方式。コストは最安だがRTOは長くなる。
脆弱性管理と物理的セキュリティ|内外の脅威を断つ対策
運用フェーズでは、外部からのサイバー攻撃だけでなく、内部関係者による不正行為や、物理的な情報持ち出しへの警戒も欠かせません。
JVNとCVSSを活用した能動的な脆弱性管理
日々発見される新たな脆弱性情報を受け身で待つのではなく、能動的に収集し、自組織への影響を評価するプロセスが必要です。日本国内において、脆弱性対策情報のポータルサイトとして機能しているのがJVN(Japan Vulnerability Notes)です。
JVNなどで公開される脆弱性情報には、深刻度を定量的に評価する共通スコアリングシステムCVSS(Common Vulnerability Scoring System)が付与されています。CVSSは以下の3つの基準で評価されます。
- 基本評価基準(Base Metrics):脆弱性そのものが持つ固有の深刻度。時間が経過しても環境が変わっても変化しません。
- 現状評価基準(Temporal Metrics):攻撃コードが出回っているか、公式なパッチがリリースされているかなど、時間の経過とともに変化する深刻度。
- 環境評価基準(Environmental Metrics):そのシステムが組織内でどれほど重要か、代替の防護策があるかなど、利用環境に応じた深刻度。
現場の運用担当者は、ベンダーが発表する「基本評価基準」のスコアだけで慌てるのではなく、自社の「環境評価基準」を加味して、真に対応を急ぐべきパッチかどうかを冷静に見極める優先順位付けのスキルが求められます。
特権ID管理(PAM)とログ監査による内部不正への備え
情報漏えいインシデントの多くは、外部からのハッキングではなく、従業員・退職者・委託先社員などの「内部関係者」による不正な持ち出しによって引き起こされています。内部不正を防ぐための技術的な要が、特権ID管理(PAM:Privileged Access Management)です。
システムの設定変更や全データの閲覧が可能な「Administrator」や「root」といった特権IDは、システム全体を意のままに操れる強力なアカウントです。この特権IDを特定の個人に固定で割り当てることは非常に危険であり、以下の運用を徹底することが求められます。
- 特権IDの使用には事前の申請と承認を必須とする
- 作業が終われば直ちにパスワードを変更し、パスワード管理システムに返却する
- 職務の分離(データベース管理者と監査ログ管理者を別の人物にするなど)を適用する
- システム操作の履歴(監査ログ)を第三者が定期的にモニタリングし、「見られている」という意識付けを行う
これらの運用を組み合わせることで、内部不正を技術的・心理的に抑止します。
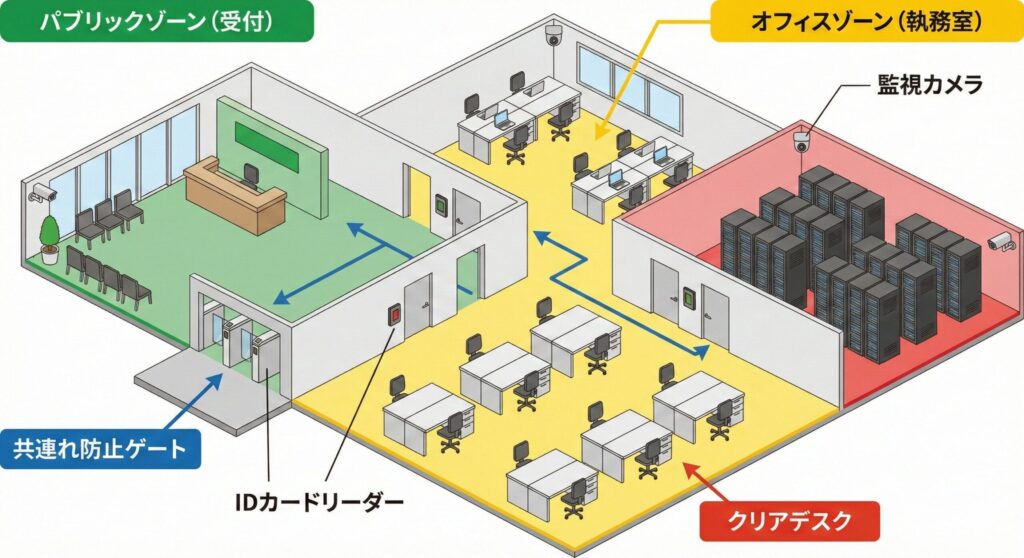
決して侮れない物理的セキュリティ(入退室管理とクリアデスク)
ネットワークをどれだけ強固なファイアウォールで守っても、攻撃者が直接オフィスに侵入してサーバーにUSBメモリを挿すことができれば、すべてのセキュリティ対策は無意味になります。物理的セキュリティは、情報保護の最後の砦です。
- 入退室管理(ゾーニング)
オフィス空間を、誰もが入れる「パブリックゾーン」、一般従業員が働く「執務ゾーン」、サーバーや重要データが保管されている「セキュリティゾーン」に分割します。ゾーンが深くなるにつれてICカード・暗証番号・生体認証(指紋や静脈)などを組み合わせた多要素認証を導入し、セキュリティレベルを段階的に高めます。 - 共連れ(Tailgating / Piggybacking)の防止
正当な権限を持つ社員がドアを開けた背後から、権限を持たない者がこっそり侵入する「共連れ」は、物理的侵入の常套手段です。一人しか通れないアンチパスバックゲートやフラッパーゲートの導入、監視カメラによる目視確認で対策します。 - クリアデスク・クリアスクリーン
離席時に机の上に機密書類やUSBメモリを放置しない「クリアデスク」、PCの画面をロックする「クリアスクリーン」は、ショルダーハック(肩越しにパスワードを盗み見る行為)などのソーシャルエンジニアリングを防ぐための極めて有効な運用ルールです。
複合シナリオで鍛える!運用フェーズの実践的思考
これまで解説した知識は、現場で直面する複合的なトラブルを解決するための思考の土台となります。知識を暗記するだけでなく、「シナリオ」として捉えることで、実践力が格段に上がります。
例として、「深夜にWebサーバーが高負荷でダウンし、再起動で復旧させた」という事象を考えてみましょう。これを単なるハードウェア障害で片付けてはいけません。複数の観点から同時に検証する必要があります。
- ログの確認:再起動する前にメモリダンプ(揮発性データの保全)は行ったか。再起動前のWebアクセスログに、DDoS攻撃や脆弱性スキャンの痕跡(異常な連続アクセス)はないか。
- パッチの状況:そのWebサーバーのOSやミドルウェアに最新のパッチが当たっていたか。資産台帳との乖離はないか。
- 事業への影響:システムが停止していた間、RTO要件は満たせていたか。BCPの発動基準に該当する事象だったか。
このように一つの事象に対して「ログ分析」「インシデントレスポンス」「パッチ管理」「BCP要件」など、複数の切り口から全体を俯瞰し、原因究明と再発防止策を組み立てる力が、運用フェーズにおける真のセキュリティ対応力です。
単一の技術を深掘りするだけでなく、知識を横断的に繋げる視点を常に意識してください。
【復習用】システム運用セキュリティ 振り返り練習問題
記事の通読、お疲れ様でした!「わかったつもり」を防ぎ、知識を確実なものにするためには、すぐのアウトプットが非常に有効です。インシデントレスポンスの鉄則やバックアップ戦略など、特に重要なポイントを全10問の練習問題にまとめました。間違えた問題は詳細な解説を読んで、しっかりと復習しましょう。
まとめ|「Assume Breach」の思想で運用の全体像を掴む
本記事で解説したシステム運用・セキュリティ対策の要点を振り返ります。
- ログとインシデント対応:平時のログ監視体制(SOC/SIEM)と、有事の際の組織的な初動対応(CSIRT/フォレンジック)を連動させることが不可欠です。
- 維持と復旧:泥臭いが確実なIT資産管理・パッチ管理、そしてRPO/RTOに基づいたバックアップとBCP/DR戦略が可用性を支えます。
- 内部と物理の防壁:CVSSを活用した脆弱性のトリアージ、特権ID管理による内部不正の抑止、ゾーニングとクリアデスクによる物理空間の保護は三位一体です。
これらはすべて、「システムはいつか必ず攻撃を受け、そして障害を起こす」という現実的な前提——Assume Breach(侵害を前提とする考え方)——に立った対策です。
完璧な防御は存在しません。だからこそ、検知・封じ込め・復旧・改善のサイクルを組織全体に根付かせることが、長期的なセキュリティ強度を高める唯一の道です。ネットワーク、Webアプリケーションの脆弱性、暗号化技術、そして今回の運用・管理と、セキュリティを構成する核心技術は一通り揃いました。次のステップでは、これらの知識を総動員し、情報セキュリティマネジメント(ISMS)の構築や各種法規への理解を深め、点と点を繋いだ盤石なセキュリティの全体像を完成させていきましょう。
学習の全体像=進むべき道筋がひと目で分かる
〈セキュリティ学習メール〉